9 R Session 03
Estimation

Materials adapted from John Drake and Pej Rohani (Drake and Rohani 2019)
9.1 Setup
Code
# Loads the datasets: flu, measles, niamey, plauge
flu <- rio::import("https://raw.githubusercontent.com/arnold-c/SISMID-Module-02_2023/main/data/flu.csv")
niamey <- rio::import("https://raw.githubusercontent.com/arnold-c/SISMID-Module-02_2023/main/data/niamey.csv")
# flu <- rio::import(here::here("data", "flu.csv"))
# niamey <- rio::import(here::here("data", "niamey.csv"))9.2 Estimating \(R_0\) Problem Background
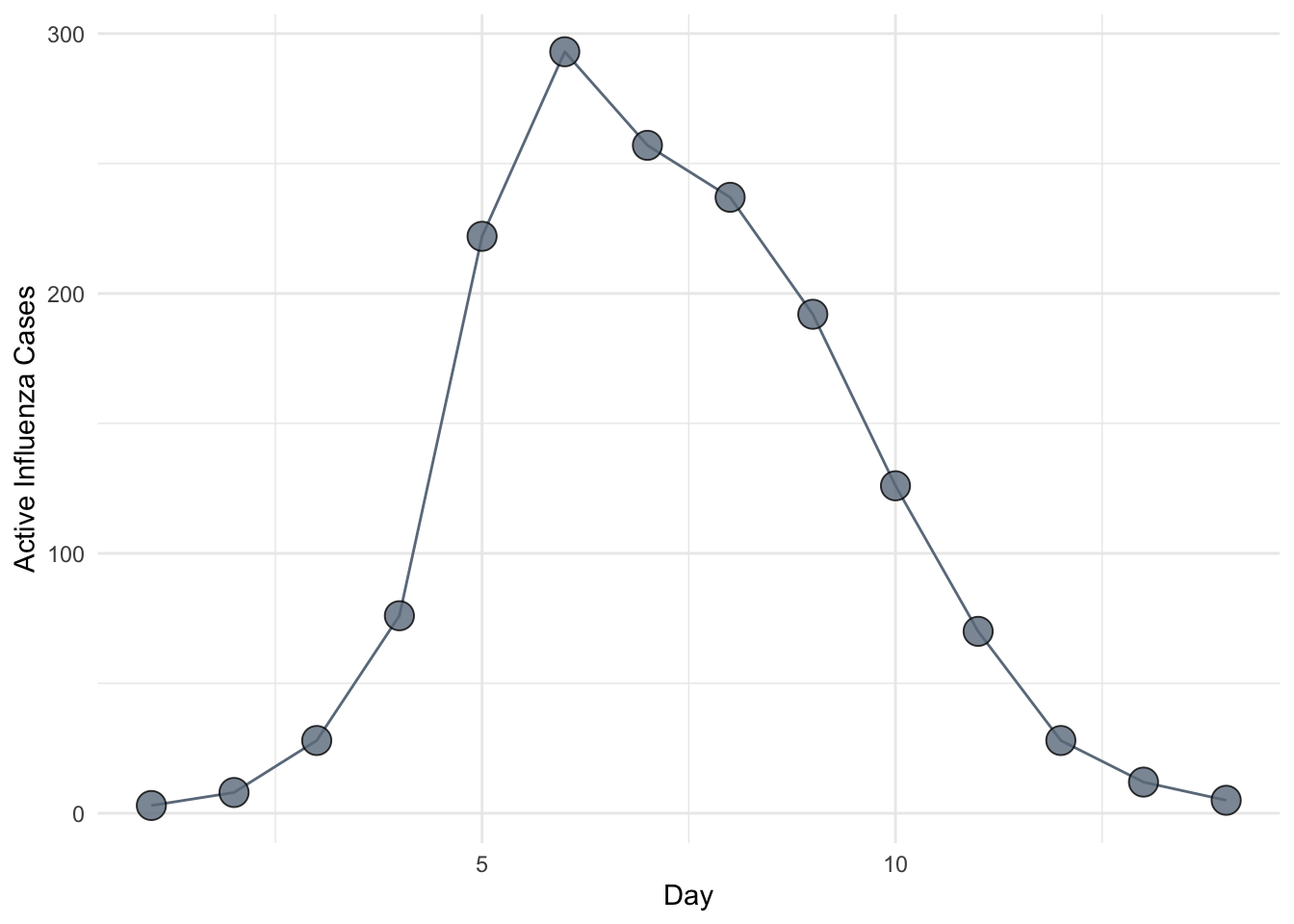
So far in this class we have focused on the theory of infectious disease. Often, however, we will want to apply this theory to particular situations. One of the key applied problems in epidemic modeling is the estimation of \(R_0\) from outbreak data. In this session, we study two methods for estimating \(R_0\) from an epidemic curve. As a running example, we will use the data on influenza in a British boarding school.
9.3 Estimating \(R_0\) From The Final Outbreak Size
Our first approach is to estimate \(R_0\) from the final outbreak size. Although unhelpful at the early stages of an epidemic (before the final epidemic size is observed), this method is nonetheless a useful tool for post hoc analysis. The method is general and can be motivated by the argument listed in (Keeling and Rohani 2008):
First, we assume that the epidemic is started by a single infectious individual in a completely susceptible population. On average, this individual infects \(R_0\) others. The probability a particular individual escaped infection is therefore \(e^{-R_0 / N}\).
If \(Z\) individuals have been infected, the probability of an individual escaping infection from all potential sources is \(e^{-Z R_0 / N}\). It follows that at the end of the epidemic a proportion \(R(\infty) = Z / N\) have been infected and the fraction remaining susceptible is \(S(\infty) = e^{-R(\infty) R_0}\), which is equal to \(2 - R(\infty)\).
\(S(\infty) = e^{-R(\infty) R_0}\) can be calculated by acknowledging that at equilibrium (\(t = \infty\)), \(S(\infty) = 1 - R(\infty) = Z / N\), so substituting \(R(\infty)\) into \(1 - e^{-Z R_0 / N}\) gives the desired result.
It could also be calculated by dividing \(\frac{\dd{S}}{\dd{t}}\) by \(\frac{\dd{R}}{\dd{t}}\):
\[\begin{aligned} \frac{\dd{S}}{\dd{R}} &= - \frac{\beta S}{\gamma} \\ &= - R_0 S \end{aligned}\]which is a separable differential equation, so can be integrated as follows:
\[\begin{aligned} - \int_{0}^{t} \frac{1}{R_0 S} \dd{S} &= \int_{0}^{t} \dd{R} \\ - \frac{1}{R_0} \left(\ln{S(t)} - \ln{S(0)} \right) &= R(t) - \cancelto{0}{R(0)} \\ \ln{S(t)} &= \ln{S(0)} - R_0 R(t) \\ S(t) &= S(0) e^{-R_0 R(t)} \end{aligned}\]Putting this together, we get:
\[ 1 - R(\infty) - e^{-R(\infty) R_0} = 0 \]
Rearranging, we have the estimator
\[ \hat{R_0} = \frac{\ln(1 - Z / N)}{-Z / N}, \]
which, in this case, evaluates to \(\frac{\ln(1 - 512 / 764)}{-512 / 764} = 1.655\).
9.3.1 Exercise 1
This equation shows the important one-to-one relationship between \(R_0\) and the final epidemic size. Plot the relationship between the total epidemic size and \(R_0\) for the complete range of values between 0 and 1.
9.4 Linear Approximation
The next method we introduce takes advantage of the fact that during the early stages of an outbreak, the number of infected individuals is given approximately as \(I(t) \approx I_0 e^{((R_0 - 1)(\gamma + \mu)t)}\). Taking logarithms of both sides, we have \(\ln(I(t)) \approx \ln(I_0) + (R_0 - 1)(\gamma + \mu)t\), showing that the log of the number of infected individuals is approximately linear in time with a slope that reflects both \(R_0\) and the recovery rate.
This suggests that a simple linear regression fit to the first several data points on a log-scale, corrected to account for \(\gamma\) and \(\mu\), provides a rough and ready estimate of \(R_0\). For flu, we can assume \(\mu =0\) because the epidemic occurred over a time period during which natural mortality is negligible. Further, assuming an infectious period of about 2.5 days, we use \(\gamma = (2.5)^{-1} = 0.4\) for the correction. Fitting to the first four data points, we obtain the slope as follows.
Code
Call:
lm(formula = log(flu[1:4]) ~ day[1:4], data = flu)
Residuals:
1 2 3 4
0.03073 -0.08335 0.07450 -0.02188
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.02703 0.10218 -0.265 0.81611
day[1:4] 1.09491 0.03731 29.346 0.00116 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.08343 on 2 degrees of freedom
Multiple R-squared: 0.9977, Adjusted R-squared: 0.9965
F-statistic: 861.2 on 1 and 2 DF, p-value: 0.001159day[1:4]
1.094913 Rearranging the linear equation above and denoting the slope coefficient by \(\hat \beta_1\) we have the estimator \(\hat R_0 = \hat \beta_1 / \gamma + 1\) giving \(\hat R_0 = 1.094913 / 0.4 + 1 \approx 3.7\).
9.4.1 Exercise 2
Our estimate assumes that boys remained infectious during the natural course of infection. The original report on this epidemic indicates that boys found to have symptoms were immediately confined to bed in the infirmary. The report also indicates that only 1 out of 130 adults at the school exhibited any symptoms. It is reasonable, then, to suppose that transmission in each case ceased once he had been admitted to the infirmary. Supposing admission happened within 24 hours of the onset of symptoms. How does this affect our estimate of \(R_0\)? Twelve hours?
9.4.2 Exercise 3
Biweekly data for outbreaks of measles in three communities in Niamey, Niger are provided in the dataframe niamey. Use this method to obtain estimates of \(R_0\) for measles from the first community assuming that the infectious period is approximately two weeks or \(\frac{14}{365} \approx 0.0384\) years.
9.4.3 Exercise 4
A defect with this method is that it uses only a small fraction of the information that might be available, i.e., the first few data points. Indeed, there is nothing in the method that tells one how many data points to use–this is a matter of judgment. Further, there is a tradeoff in that as more and more data points are used the precision of the estimate increases, but this comes at a cost of additional bias. Plot the estimate of \(R_0\) obtained from \(n=3, 4, 5, ...\) data points against the standard error of the slope from the regression analysis to show this tradeoff.
9.5 Estimating dynamical parameters with least squares
The objective of the previous exercise was to estimate \(R_0\). Knowing \(R_0\) is critical to understanding the dynamics of any epidemic system. It is, however, a composite quantity and is not sufficient to completely describe the epidemic trajectory. For this, we require estimates for all parameters of the model. In this exercise, we introduce a simple approach to model estimation called least squares fitting, sometimes called trajectory matching. The basic idea is that we find the values of the model parameters that minimize the squared differences between model predictions and the observed data. To demonstrate least squares fitting, we consider an outbreak of measles in Niamey, Niger, reported on by (Grais et al. 2006).
Code
# Replace an "NA"
niamey[5, 3] <- 0
niamey_df <- niamey %>%
# Rename columns to remove automatic "V1" etc columns names
rename_with(., ~paste0("Site_", str_remove(.x, "V"))) %>%
# Add a column for the biweekly time period
mutate(biweek = 1:16) %>%
# Convert to long format for plotting
pivot_longer(
cols = contains("Site"),
names_to = "site",
values_to = "cases"
)Code
# Create a vector of colors for each site in the Niamey dataset
niamey_site_colors <- RColorBrewer::brewer.pal(3, "Dark2")
# Assign names to the colors
names(niamey_site_colors) <- unique(niamey_df$site)
# Create a vector of labels for each site for nicer plotting legends
niamey_site_labels <- str_replace_all(names(niamey_site_colors), "_", " ")
names(niamey_site_labels) <- names(niamey_site_colors)Code
ggplot(
niamey_df,
aes(x = biweek, y = cases, color = site, fill = site, group = site)
) +
geom_line() +
geom_point(shape = 21, size = 5, alpha = 0.8) +
scale_color_manual(
values = niamey_site_colors,
aesthetics = c("color", "fill"),
labels = niamey_site_labels
) +
guides(color = "none") +
labs(x = "Biweek", y = "Number of Cases", fill = "Site Number") +
theme(legend.position = "bottom")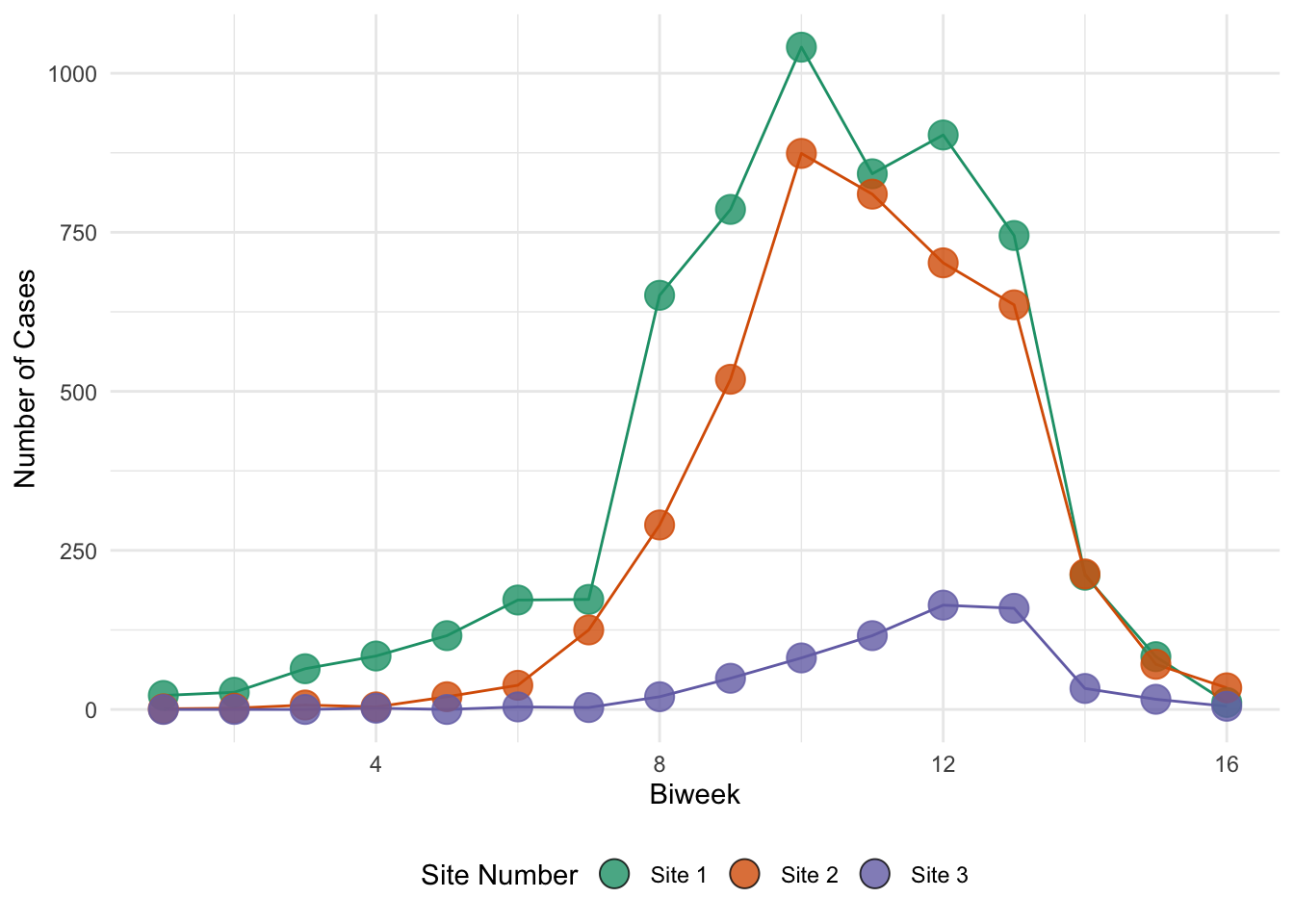
9.6 Dynamical Model
First, we write a specialized function for simulating the SIR model in a case where the removal rate is “hard-wired” and with no demography.
Code
#' Basic SIR model
#'
#' A basic SIR model with no demographic structure to be used in deSolve
#'
#' @param time deSolve passes the time parameter to the function.
#' @param state A vector of states.
#' @param params The beta parameter
#' @param ... Other arguments passed by deSolve.
#'
#' @return A deSolve matrix of states at each time step.
#' @examples
#' sir_params <- 0.0005
#' sir_init_states <- c(S = 5000, I = 1, R = 0)
#' sim_times <- seq(0, 16 / 365, by = 0.1 / 365)
#'
#' sir_sol <- deSolve::ode(
#' y = sir_init_states,
#' times = sim_times,
#' func = closed_sir_model,
#' parms = sir_params
#' ))
closed_sir_model <- function (time, state , params, ...) {
# Unpack states
S <- state["S"]
I <- state["I"]
# Unpack parameters
beta <- params
dur_inf <- 14 / 365
gamma <- 1 / dur_inf
new_inf <- beta * S * I
# Calculate the ODEs
dSdt <- -new_inf
dIdt <- new_inf - (gamma * I)
# Return the ODEs
return(list(c(dSdt, dIdt, new_inf)))
}9.7 Interactive Optimization
Code
Code
Code
Code
9.8 Objective Function
Now we set up a function that will calculate the sum of the squared differences between the observations and the model at any parameterization (more commonly known as “sum of squared errors”). In general, this is called the objective function because it is the quantity that optimization seeks to minimize.
Code
#' Calculate the Sum of Squared Errors
#'
#' A function to take in biweekly incidence data, and SIR parameters, and
#' calculate the SSE
#'
#' @param params A vector of parameter values
#' @param data A dataframe containing biweekly incidence data in the case column
#'
#' @return The SSE of type double
#' @examples
sse_sir <- function(params, data){
# Convert biweekly time series into annual time scale
# Daily time scale has requires beta values to be too small - doesn't
# optimize well
dt <- 0.01
max_biweek <- max(data$biweek)
t <- seq(0, max_biweek * 14, dt) / 365
# Extract the number of observed incidence
obs_inc <- data$cases
# Note the parameters are updated throughout the optimization process by
# the optim() function
# Unpack the transmission parameter and exponentiate to fit on ln scale
beta <- exp(params[["beta"]])
# Unpack the initial states and exponentiate to fit on normal scale
S_init <- exp(params[["S_init"]])
I_init <- exp(params[["I_init"]])
# Fit SIR model to the parameters
sol <- deSolve::ode(
y = c(S = S_init, I = I_init, new_inf = 0),
times = t,
func = closed_sir_model,
parms = beta,
# Use rk4 as fixed time steps, which is important for indexing
method = "rk4"
)
# Extract the cumulative incidence
cum_inc <- sol[, "new_inf"]
# Find the indices of the cumulative incidence to extract
biweek_index <- seq(1, max_biweek) * (14 / dt) + 1
# Index cumulative incidence to get the values at the end of the biweeks
biweek_cum_inc <- cum_inc[biweek_index]
# Calculate the biweekly incidence by using the difference between
# consecutive biweeks. Need to manually prepend first week's incidence
# and add in the initial number of infectious individuals, as ODE model
# only returns the cumulative differences, which is 0 at the start.
biweek_inc <- c(biweek_cum_inc[1] + I_init, diff(biweek_cum_inc, lag = 1))
# return SSE of predicted vs observed incidence
return(sum((biweek_inc - obs_inc)^2))
}Notice that the code for sse_sir() makes use of the following modeling trick. We know that \(\beta\), \(S_0\), and \(I_0\) must be positive, but our search to optimize these parameters will be over the entire number line. We could constrain the search using a more sophisticated algorithm, but this might introduce other problems (i.e., stability at the boundaries). Instead, we parameterize our objective function (sse_sir) in terms of some alternative variables \(\ln(\beta)\), \(\ln(S_0)\), and \(\ln(I_0)\). While these numbers range from \(-\infty\) to \(\infty\) (the range of our search) they map to our model parameters on a range from \(0\) to \(\infty\) (the range that is biologically meaningful).
9.9 Optimization
Our final step is to use the function optim to find the values of \(\beta\), \(S_0\), and \(I_0\) that minimize the sum of squared errors as calculated using our function.
Finally, we plot these fits against the data.
Code
# Initial guess
sse_optim_params <- c(beta = log(0.055), S_init = log(5000), I_init = log(1))
# Create a dataframe of optimized parameters
niamey_optims <- niamey_df %>%
# Create a nested dataframe i.e. one row for each site, and the data column
# now is a list column that contains a separate dataframe of times and
# cases for each site
nest(data = -site) %>%
mutate(
# Map the optim() function call to each of the separate dataframes
# stored in the nested data column we just created
fit = map(data, ~optim(sse_optim_params, sse_sir, data = .x)),
# Map the exp() function to each of the model fits just created, and
# output to a dataframe instead of a list (like in map()), for easier
# use in the plottinge predictions later
map_dfr(fit, ~exp(.x$par))
)Code
niamey_optims %>%
select(-c(data, fit)) %>%
mutate(site = str_replace_all(site, "_", " ")) %>%
gt() %>%
fmt_number(columns = -site, decimals = 3) %>%
fmt_scientific(columns = beta, decimals = 3) %>%
# Relabel the column headers
cols_label(
site = md("**Site**"),
beta = md("**Beta**"),
S_init = md("**Initial S**"),
I_init = md("**Initial I**")
) %>%
# Apply style to the table with gray alternating rows
opt_stylize(style = 1, color = 'gray') %>%
# Increate space between columns
opt_horizontal_padding(scale = 3) %>%
cols_align("center")| Site | Beta | Initial S | Initial I |
|---|---|---|---|
| Site 1 | 5.370 × 10−3 | 8,566.648 | 1.349 |
| Site 2 | 8.317 × 10−3 | 5,961.388 | 0.201 |
| Site 3 | 7.134 × 10−2 | 792.990 | 0.001 |
You may have noticed that you can achieve slightly different results for the optimal parameter values using the interactive plot than are being presented here (though they are very similar). This is because while the optimization code is running in R, the interactive plot and the calculation of the SSE is implemented using JavaScript. Therefore, despite using the same underlying model structure, the answers will vary slightly, because the ODE solvers are different, resulting in different model simulations. The difference is not enough to be concerned with here, but it is a point that’s worth being aware of when you build your own models - you may want to perform sensitivity to confirm that your model implementation is not driving the magnitude of the results you see, and the inferences you make.
Code
niamey_predictions <- niamey_optims %>%
mutate(
# For each of the different site's nested dataframes, fit the SIR model
# with the optimal parameters to get best fit predictions
predictions = pmap(
.l = list(
S_init = S_init,
I_init = I_init,
beta = beta,
time_data = data
),
.f = function(S_init, I_init, beta, time_data) {
site_times <- time_data$biweek * 14 / 365
# Return a dataframe of model solutions
as_tibble(ode(
y = c(S = S_init, I = I_init, new_inf = 0),
times = site_times,
func = closed_sir_model,
parms = beta,
hmax = 1/120
)) %>%
# Make sure all values are numeric for plotting purposes
mutate(across(everything(), as.numeric)) %>%
mutate(
incidence = ifelse(row_number() == 1, new_inf[1], diff(new_inf, lag = 1))
)
}
)
) %>%
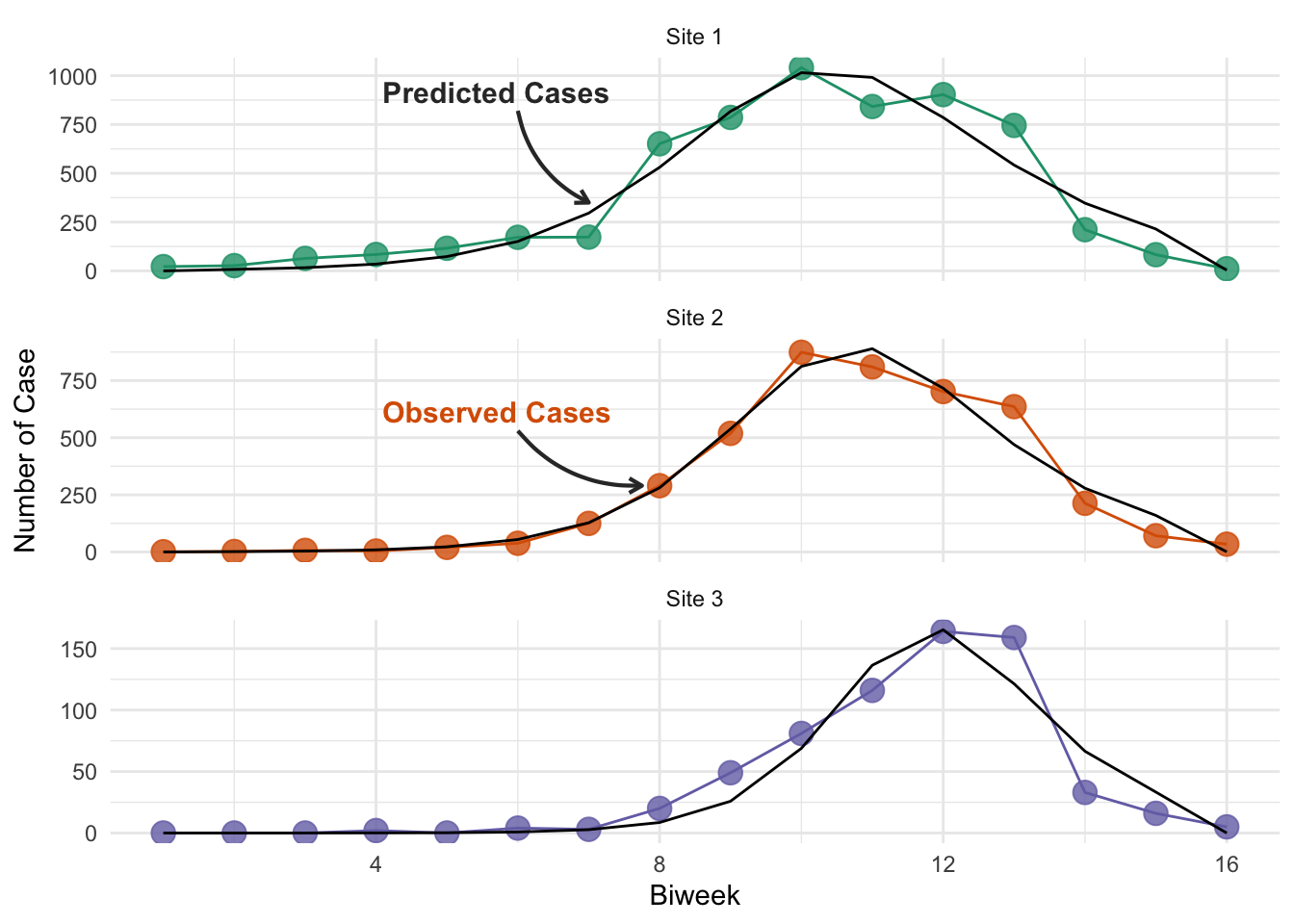
unnest(c(data, predictions))An important point to note is that our data is biweekly incidence (new cases in time period), whereas out SIR model produces prevalence (total cases at any time point). To account for this, our SIR model returns the cumulative incidence (line 32 of the model code), and our objective function extracts the biweekly incidence (lines 41-54), to ensure we are fitting the same data! This is a common source of error in interpretation when people fit models to data.
Code
# Create a dataframe to store the positions of the text labels
niamey_preds_labels <- tibble(
site = c("Site_1", "Site_2"),
x_label = c(6.5, 6.5),
x_arrow_just = c(-0.5, -0.5),
x_arrow_end = c(7, 7.75),
y_label = c(900, 600),
y_arrow_just = c(-80, -70),
y_arrow_end = c(350, 290),
commentary = c("**Predicted", "**Observed"),
color = c("grey20", niamey_site_colors["Site_2"])
)
ggplot(niamey_predictions, aes(x = biweek, group = site)) +
# Plot the actual data in color
geom_line(aes(y = cases, color = site)) +
geom_point(aes(y = cases, color = site), size = 4, alpha = 0.8) +
# Plot the best-fit model predictions in black
geom_line(aes(y = incidence), color = "black") +
scale_color_manual(
values = niamey_site_colors, aesthetics = c("color", "fill")
) +
# Place each site on it's own subplot and change labels
facet_wrap(
~site, ncol = 1, scales = "free_y",
labeller = as_labeller(niamey_site_labels)
) +
labs(x = "Biweek", y = "Number of Case") +
theme(legend.position = "none") +
ggtext::geom_textbox(
data = niamey_preds_labels,
aes(
label = paste0(
"<span style = \"color:",
color,
"\">",
commentary,
" Cases**",
"</span>"
),
x = x_label, y = y_label
),
size = 4, fill = NA, box.colour = NA
) +
geom_curve(
data = niamey_preds_labels,
aes(
x = x_label + x_arrow_just, xend = x_arrow_end,
y = y_label + y_arrow_just, yend = y_arrow_end
),
linewidth = 0.75,
arrow = arrow(length = unit(0.2, "cm")),
curvature = list(0.25),
color = "grey20"
)
9.9.1 Exercise 5
To make things easier, we have assumed the infectious period is known to be 14 days. In terms of years, \(\text{D} = \frac{14}{365} \approx 0.0384\), and the recovery rate is the inverse i.e., \(\gamma = \frac{14}{365}\). Now, modify the code above to estimate \(\gamma\) and \(\beta\) simultaneously.
9.9.2 Exercise 6
What happens if one or both of the other unknowns (\(S_0\) and \(I_0\)) is fixed instead of \(\gamma\)?